DisplayトレイトとDebugトレイト、使い方と表示 #Rust

... doesn't implement って言われているコードがいたのでこの記事を書いてみることにしたDisplay (required by ...)
↑スクショではBuildErrorという型の中身を出力すべくpanic!("{}", build_error)*1相当のことをしているのだけど、"{}"を使えるのはDisplayトレイトを実装した型のみなのでエラーが出ている。ということで、Displayの実装についてコードで確認してみよう
nameというフィールドのみ持ったPersonというストラクトの内容を標準出力してみる
#[derive(Debug)] // Debugを使うにはこれを追加するだけ pub struct Person { name: String, } // Displayは次のようにトレイトを実装する impl Display for Person { fn fmt(&self, f: &mut Formatter<'_>) -> std::fmt::Result { write!(f, "The name of this person is {}", &self.name) } } fn main() { let person = Person { name: "はなこ".to_string() }; println!("{:?}", person); // Debugトレイトの実装を使う println!("{}", person); // Displayトレイトの実装を使う }
上記の実行結果はこうなる
Person { name: "はなこ" }
The name of this person is はなこ
Debugはデフォルト実装があるため、アノテーションを付けるとすぐに使える。デバッグを楽にするのが目的なので中身の詳細をそのまま表示する。publicな型であれば実装しておくのが基本となるDisplayにはデフォルト実装がなく、必ず自ら実装する必要がある。必要な型にのみ実装し、出力したい文字列のフォーマットを実現する
ちなみにDebug を使ったときに {:?}や{:#?}*2で出力するけど、このハテナの意味は次のページに書いてある。
nothing ⇒
Display
? ⇒Debug
x? ⇒Debugwith lower-case hexadecimal integers
X? ⇒Debugwith upper-case hexadecimal integers
o ⇒Octal
x ⇒LowerHex
X ⇒UpperHex
p ⇒Pointer
b ⇒Binary
e ⇒LowerExp
E ⇒UpperExp
という風にあるトレイトを実装した型をフォーマットしたい時にどう書くべきかの対応表があって便利!
GitHub - トピックブランチ(フィーチャーブランチ)が古い時はPRをマージできないようにする
2つのPRを同じようなタイミングでマージしたせいでmainブランチでコンパイルエラーが発生すると言う事件に遭遇した。
これが起こりうるのは何もマージのタイミングが重なった時とは限らないし、トピックブランチは更新しておいてPR内で必要なチェックを済ませたいよね。
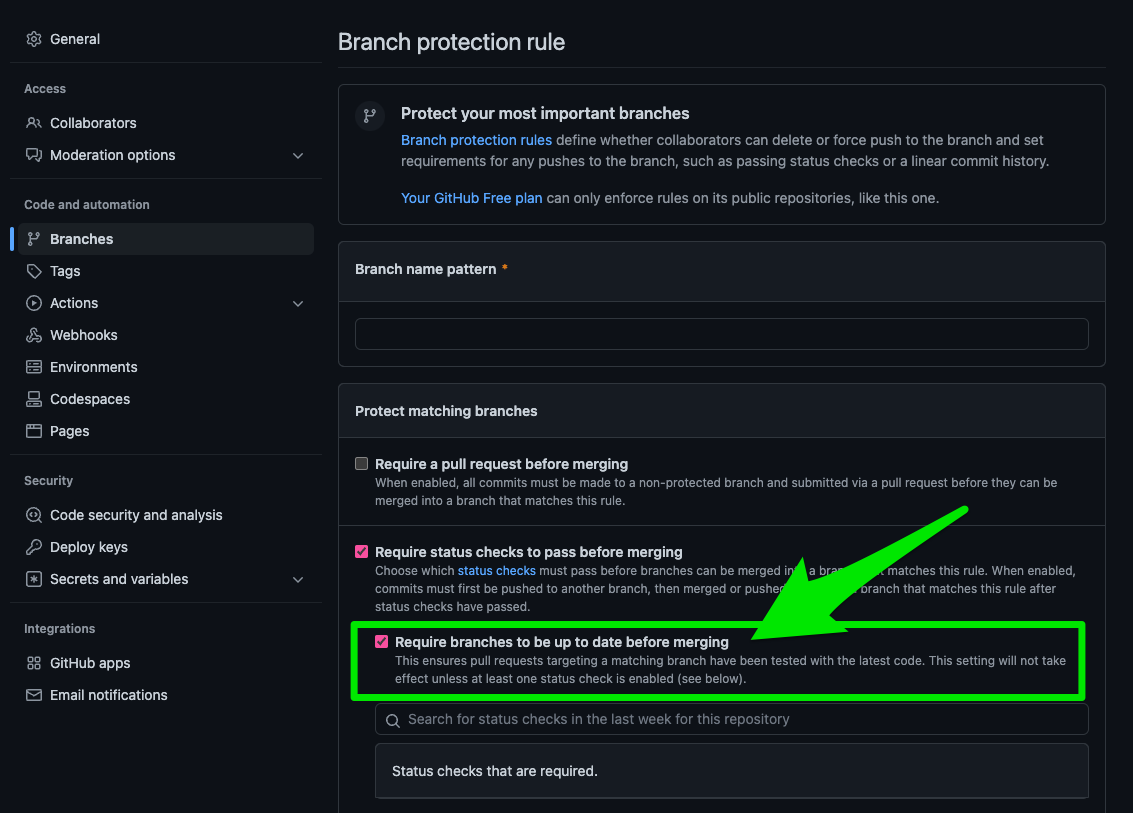
ということで、このオプションをオンにしておけばいいらしい。いかにも存在しそうな機能だけど、初めて認識したー!ありがとう。
英語を自習するだけの会を開催した。続けたい #gaya2english
英語ができないできないと言う割にオフの時間に全然努力していないので、勉強を始めることにした。強制的に時間を設けるべく勉強会を立てたら3人もの方が集まってくださった!
私は家に長年積まれていたこの本を使って、ネイティブのマネをして音読し続けるという時間にした。
(リンクは #PR です)
やってみて改めて思ったんだけど、自分は英語を話すときのリズムがネイティブのそれとは程遠い。ひとつひとつの単語を発音できたとしても、つなげ方や全体のイントネーションがおかしくて通じないことってたまにあるのよね。
サンプル音源の完コピを目指す中で、前置詞や関係代名詞の前でワンクッション入れることが多いんだなと感じた。いったんそこで文が終わったかのように下がり口調になるね。←文面だと伝わらないが…w得られたものは大きい!
そして、参加者の方が勉強会の時間を使ってブログを書いていたんだけど、「寝ぼけた頭で英語を聞く」というのがいいらしくやってみたい。まだ覚醒していないからすんなり英語が入ってくるとか…!面白いね。 note.com
この方もそうだけど、結局継続が力なんだよな。方法論とか良い教材とか情報出回ってるけど、何をやるにしても続けるかどうかにほぼかかっている気がする。
続けるのが苦手な私には勉強会がとても有意義だった。またやろう!
WSLでDockerを使う
使っているディストリビューションはUbuntu 22.04です。
Docker Desktopを使わず、WSLの中にDockerをインストールする方法もあるようなのですが(普通にLinuxを使うのと同様)、上記公式ドキュメントにある通りの方法で上手くいったのでそのまま使ってます。
Docker Desktopの設定
- Use the WSL 2 based engine
- Enable integration with my default WSL distro
にチェックをつけます(スクショは公式ドキュメント内にあります)。
WSLの設定
ディストロのバージョンをWSL 2にする
wsl -l --verbose
の結果、Ubuntuが1になっている場合、そのままではDocker Desktopとインテグレーションできないので
wsl --set-version Ubuntu 2
を実行します。ちなみに
wsl --set-default-version 2
と実行しておけば、それ以降作られるディストロはバージョン2となるようです。
トラブルシューティング
初めてset-versionを実行したとき、
$ wsl --set-version Ubuntu 2 Conversion in progress, this may take a few minutes... For information on key differences with WSL 2 please visit https://aka.ms/wsl2 The operation timed out because a response was not received from the virtual machine or container.
みたいな結果に遭遇しました。次のコマンドでWSLを再起動したら直ったのでヨシ。
wsl --shutdown
使いたいディストロをデフォルトにする
wsl --set-default Ubuntu
これでUbuntuがWSLにおいてデフォルトで使われるようになります。
ここまで設定したら、Ubuntuにログインし直すとDockerが使えるようになってました!
WSLの中でapt installとかするんじゃなくてDocker Desktopでデフォルトのディストロ使うっていう設定にした場合、dockerがsudoいらずだった🤔🐳合ってるのかな〜https://t.co/D0qScsGhh3
— よこな / Ayana (@ihcomega) February 2, 2023
(わからない)
WSL2 (Windows Subsystems for Linux) のセットアップ完了!簡単だ
簡単すぎて書くことがほとんどないありがとう。
公式ドキュメント↑に沿って試したらすぐ使えてとっても便利!自プロジェクトの環境構築↓も無事出来た。
ファイルはWindows側のどこに保存してるんだろう?とか気になったけど、
この記事にあるとおり確認したら「ネットワーク」上にあった。ネットワークドライブか、謎が深まる(どうなってるんだという詳細をもう少し知りたい気がする)。
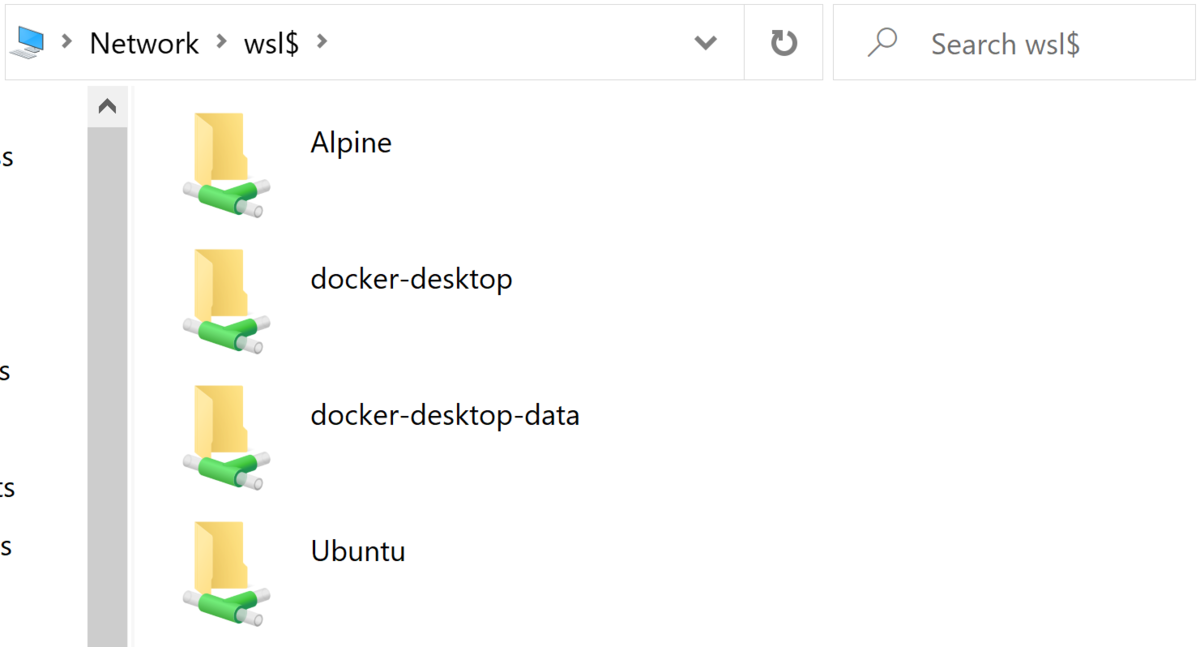
(Docker Desktopもここにいるのか!)
key=value をファイルに羅列しシェル変数を一気に適用する( . ドットコマンドを使う)
あるファイルが
exampleという名前で- 中身が
key1=value1 key2=value2 key3=value3
の時
. /path/to/example
(↑小さいけど先頭にピリオドがあるよ!)
って実行すれば key1, key2, key3はシェル変数として登録されることを知った。
$ echo $key1 value1 $ echo $key2 value2 $ echo $key3 value3
. はカレントシェルでファイルの中身を実行するという意味らしい。なので、もちろん用途はシェル変数の作成に留まらずコマンドが実行できる。
つまりsourceコマンドと同じ役割なんだけど、sourceコマンドはbashでしか使えない(shでは無理)らしい。
ソースコードコメント少なめの文化に触れている。しばらく試してみよう
見ているプロジェクト、自分の感覚では結構ソースコードコメントがない(皆無ってわけじゃないけど体感少ない)。前職は金融系ではちゃめちゃに複雑な業務知識が多かったのもあるけど、皆で丁寧にコメントやドキュメントを書きまくる文化があった。クラスやフィールドの説明も全部あったし、メソッドにもどういう理由で何がしたいかとかwikiへのリンクとかが添えられていた記憶がある。
今は
などの理由でソースコードコメントがあまりない。少なくとも前の組織に比べると。あ、ちなみにコードとは別に、ドキュメントは積極的に作成する風潮がしっかりある。
私はソースコードコメント書きまくるの肯定派だった(ので上について聞いてみたのだ)けど、話してみると
- コメント書く派:命名やロジックの工夫でメンテナビリティ保てるのが理想。でも現実的には情報が落ちちゃうからコメントも必要だよね
- 一方書かない派:コメントがロジックを追従して綺麗に維持できるのが理想。でも現実的には乖離するから命名とかで頑張るしかないよね
ということなのかなと考える。今のところチームは後者寄りのスタンス。
これまで私が書く派全力推しだったのは何故だか考えてみると、「乖離しちゃう」課題は乗り越えられると思っていたからだ。コメントを残す合意さえあれば、遅くともレビューの時点で更新漏れに気付ける。このペインポイントは十分カバーできるし、時間や労力はかかっても多くの人が関わって長くプロジェクトを続けたいなら得られるものの方が大きいという主張を持っていたのだと思う。
この議論についてはTwitterとかでも散々されていると思うんだけど改めて考える機会が来たというお話でしたん。
幸い前述の通りドキュメントはがんがん残そうどんどん共有しようという文化なので、それと合わせてコメントについては上記の方針でやっていくとどんな経験をするか、しばらく試してみることにする。日々、皆と色々相談しながらやっていくよー!